






Suyash Bagad
Research Team
Suyash Bagad
Invisible Garden 2024
Ingonyama
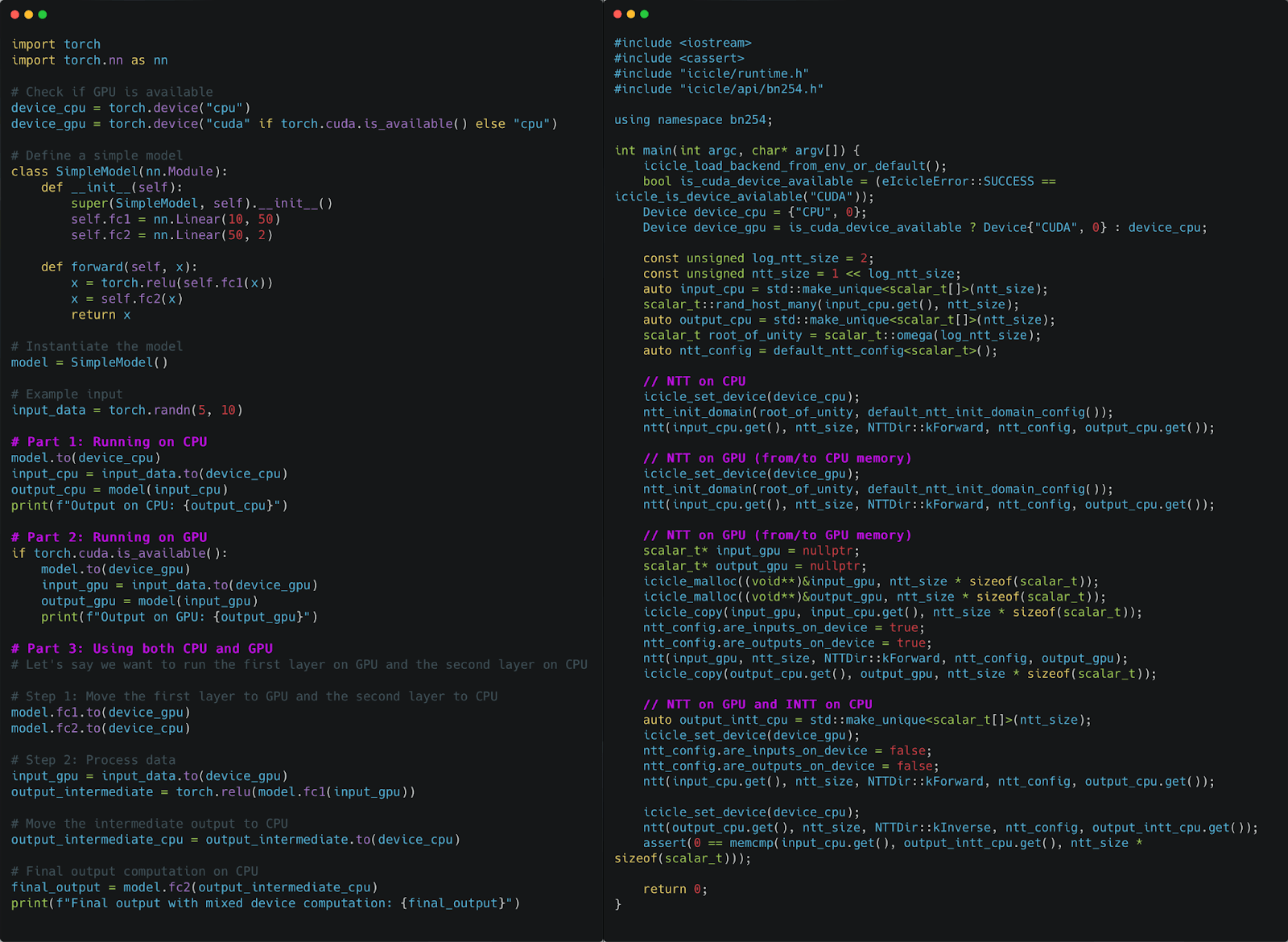
Nooo..to make my ZK prover faster I need to accelerate MSM and NTT for the BN254 curve. I need GPU/CPU coordination and I'll need to learn CUDA while my prover is written in Rust. Ughhh
Modular
arithmetic
NTT
Merkle
trees
MSM
G1 & G2
ECNTT
Hashes
Vector
ops
EC Group operations
Linear
Algebra
Polynomial API
(Univariate and Multivariate)
C++
Rust
Go
Credit: Karthik Inbasekar
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Host
poly 1
poly 2
poly 10
Device
Can we perform computation and
data transfer simultaneously in icicle?
Host
poly 1
poly 2
poly 10
Device
One for compute,
one for data transfer
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
Host
poly 1
poly 2
poly 10
Device
poly 3
How did we read and write simultaneously?
Device
New input
Output
Device
New input
Output
Device
New input
Output
Device
New input
Output
Device
New input
Output
Device
New input
Output
int main(int argc, char* argv[])
{
try_load_and_set_backend_device(argc, argv);
// set these parameters to match the desired NTT size and batch size
const unsigned log_ntt_size = 20;
const unsigned batch_size = 16;
scalar_t basic_root = scalar_t::omega(log_ntt_size);
const unsigned ntt_size = 1 << log_ntt_size;
std::cout << "log NTT size: " << log_ntt_size << std::endl;
std::cout << "Batch size: " << batch_size << std::endl;
// Create separate streams for overlapping data transfers and kernel execution.
icicleStreamHandle stream_compute, stream_h2d, stream_d2h;
ICICLE_CHECK(icicle_create_stream(&stream_compute));
ICICLE_CHECK(icicle_create_stream(&stream_h2d));
ICICLE_CHECK(icicle_create_stream(&stream_d2h));
// Initialize NTT domain
std::cout << "Init NTT domain" << std::endl;
auto ntt_init_domain_cfg = default_ntt_init_domain_config();
// set CUDA backend specific flag for init_domain
ConfigExtension backend_cfg_ext;
backend_cfg_ext.set(CudaBackendConfig::CUDA_NTT_FAST_TWIDDLES_MODE, true);
ntt_init_domain_cfg.ext = &backend_cfg_ext;
ICICLE_CHECK(bn254_ntt_init_domain(&basic_root, &ntt_init_domain_cfg));
std::cout << "Concurrent Download, Upload, and Compute In-place NTT" << std::endl;
int nof_blocks = 32;
int block_size = ntt_size * batch_size / nof_blocks;
std::cout << "Number of blocks: " << nof_blocks << ", block size: " << block_size << " Bytes" << std::endl;
// on-host pinned data
scalar_t* h_inp[2];
scalar_t* h_out[2];
for (int i = 0; i < 2; i++) {
h_inp[i] = new scalar_t[ntt_size * batch_size];
h_out[i] = new scalar_t[ntt_size * batch_size];
}
// on-device in-place data
// we need two on-device vectors to overlap data transfers with NTT kernel execution
scalar_t* d_vec[2];
for (int i = 0; i < 2; i++) {
ICICLE_CHECK(icicle_malloc((void**)&d_vec[i], sizeof(scalar_t) * ntt_size * batch_size));
}
// initialize input data
initialize_input(ntt_size, batch_size, h_inp[0]);
initialize_input(ntt_size, batch_size, h_inp[1]);
// ntt configuration
NTTConfig<scalar_t> config_compute = default_ntt_config<scalar_t>();
config_compute.batch_size = batch_size;
config_compute.are_inputs_on_device = true;
config_compute.are_outputs_on_device = true;
config_compute.is_async = true;
config_compute.stream = stream_compute;
// backend specific config extension
ConfigExtension ntt_cfg_ext;
ntt_cfg_ext.set(CudaBackendConfig::CUDA_NTT_ALGORITHM, CudaBackendConfig::NttAlgorithm::MixedRadix);
config_compute.ext = &ntt_cfg_ext;
for (int run = 0; run < 10; run++) {
int vec_compute = run % 2;
int vec_transfer = (run + 1) % 2;
std::cout << "Run: " << run << std::endl;
std::cout << "Compute Vector: " << vec_compute << std::endl;
std::cout << "Transfer Vector: " << vec_transfer << std::endl;
START_TIMER(inplace);
bn254_ntt(d_vec[vec_compute], ntt_size, NTTDir::kForward, &config_compute, d_vec[vec_compute]);
// we have to delay upload to device relative to download from device by one block: preserve write after read
for (int i = 0; i <= nof_blocks; i++) {
if (i < nof_blocks) {
// copy result back from device to host
ICICLE_CHECK(icicle_copy_async(
&h_out[vec_transfer][i * block_size], &d_vec[vec_transfer][i * block_size], sizeof(scalar_t) * block_size,
stream_d2h));
}
if (i > 0) {
// copy next input from host to device to alternate buffer
ICICLE_CHECK(icicle_copy_async(
&d_vec[vec_transfer][(i - 1) * block_size], &h_inp[vec_transfer][(i - 1) * block_size],
sizeof(scalar_t) * block_size, stream_h2d));
}
// synchronize upload and download at the end of the block to ensure data integrity
ICICLE_CHECK(icicle_stream_synchronize(stream_d2h));
ICICLE_CHECK(icicle_stream_synchronize(stream_h2d));
}
// synchronize compute stream with the end of the computation
ICICLE_CHECK(icicle_stream_synchronize(stream_compute));
END_TIMER(inplace, "Concurrent In-Place NTT");
}
// Clean-up
for (int i = 0; i < 2; i++) {
ICICLE_CHECK(icicle_free(d_vec[i]));
delete[] (h_inp[i]);
delete[] (h_out[i]);
}
ICICLE_CHECK(icicle_destroy_stream(stream_compute));
ICICLE_CHECK(icicle_destroy_stream(stream_d2h));
ICICLE_CHECK(icicle_destroy_stream(stream_h2d));
return 0;
}
// Given polynomials p1 and p2:
// Addition and multiplication: (p1 + p2)^2
let poly_sum_squared = &(&p1 + &p2) * &(&p1 + &p2);
// Subtraction: (p1 - p2)^2
let poly_diff_squared = &(&p1 - &p2) * &(&p1 - &p2);
// Check the identity: (p1 + p2)^2 + (p1 - p2)^2 = 2 * (p1^2 + p2^2)
let identity1_left = &poly_sum_squared + &poly_diff_squared;
let identity1_right = &(&(&p1 * &p1) + &(&p2 * &p2)) * &constant_two;
// Check the identity: (p1 + p2)^2 - (p1 - p2)^2 = 4 * p1 * p2
let identity2_left = &poly_sum_squared - &poly_diff_squared;
let identity2_right = &(&p1 * &p2) * &constant_four;
v1
Accelerated primitives
v2
Polynomial API
v3
Multi-platform
By Suyash Bagad



